|
Alle origini dell’Informatica Umanistica:
i database e la digitalizzazione

L’Informatica Umanistica è una disciplina bifronte che, come rivela il suo stesso nome, è nata sulla frontiera tra scienze umane e scienze esatte, collocando in opposizione elementi certi, quantificabili e interpretazioni che sembrano sfuggire ai requisiti dell’oggettività.
Le perplessità che questa bicefalia ha suscitato fin dai suoi primi sviluppi nella comunità accademica, non hanno tuttavia impedito l’instaurarsi di un fecondo rapporto tra scienze storico-filologiche e tecnologie informatiche, non appena il computer si è reso ragionevolmente disponibile, mediato dalle intuizioni e dalle sperimentazioni di alcuni pionieri.
 |
L’esempio più autorevole è probabilmente quello rappresentato dall’Index Thomisticus,monumentale lemmatizzazione dell’opera omnia di Tommaso d’Aquino ideata da padre Roberto Busa già nel 1948 ma attiva a partire dalla metà degli anni Sessanta del Novecento, proprio grazie all’utilizzo del primo mainframe in commercio, l’IBM 360. |
|
R. Busa, Index Thomisticus Sancti Thomae Aquinatis Operum Omnium Indices ed concordantiae, 56 voll., Stuttgart-Bad-Cannstatt, Frommann-Holzboog 1974.
Dopo di lui, numerosi sono stati gli studiosi che hanno prodotto indici e concordanze di autori o di corpora: per l’Italia, basterà ricordare l’indice e concordanza dei grammatici latini, curata da Marinone, cfr. N. Marinone, V. Lomanto, Index grammaticus. An index to Latin Grammar Texts, 3 voll., Hildesheim, Olms Weidmann 1990 (Alpha-omega. Reihe A, Lexika, Indizes, Konkordanzen zur klassischen Philologie). |

Un moderno Mainframe
Il progetto, inizialmente avviato su schede perforate e successivamente su nastro magnetico, venne completato nel 1980, con la stampa in 56 volumi; successiva fu invece la versione ipertestuale, consultabile interattivamente e pubblicata su Cd-Rom nel 1989.
Nel 2005 ha fatto il suo debutto la versione Web dell’Index Sponsorizzata dalla Fundación Tomás de Aquino e dalla CAEL (Associazione per la Computerizzazione delle Analisi Ermeneutiche Lessicologiche), la progettazione è stata affidata a E. Alarcón e E. Bernot, in collaborazione con Roberto Busa. Per la descrizione del metodo seguito per realizzare l’Index Thomisticus, cfr. R. Busa, Fondamenti di informatica linguistica, Milano, Vita e Pensiero 1987 (Trattati e manuali), pp. 412. |
Tra gli anni Sessanta e gli anni Settanta, l’adozione di metodi statistici e di linguaggi matematici resa possibile dall’utilizzo dei mainframe, caratterizzarono soprattutto la cosìdetta New Economic History o cliometria, una metodologia di ricerca applicata all’analisi economica attuata a partire dall’immissione nella memoria dell’elaboratore di imponenti serie numeriche, tratte per lo più dagli archivi catastali e dalle fonti demografiche, al fine di ottenere risultanze statistiche applicabili ai diversi periodi storici. Tra gli esempi italiani vanno annoverate le ricerche coordinate da Michele Luzzati sulle fonti fiscali e battesimali pisane del XV e XVI secolo e quelle, ormai leggendarie, compiute da David Herlihy e Christiane Klapish-Zuber sul catasto fiorentino del 1427. |
|
Proprio questo lavoro illumina su alcuni dei più rilevanti problemi connessi all’utilizzo di tecniche informatiche per analisi di storia quantitativa all’epoca in questione.
Un passaggio fondamentale nelle procedure di lavoro con un mainframe – che, è bene ricordarlo, negli anni ’60 non erano supportati da un’interfaccia utente – era infatti costituito dalla codificazione dei dati su schede perforate, mentre l’esecuzione del programma avveniva solamente in modalità batch, restituendo i risultati tramite unità di telescriventi su supporto cartaceo. |
 |
Il termine batch (letteralmente: infornata) viene usato per indicare un particolare modo di gestire le operazioni di un sistema di calcolo: in sostanza tutta la sequenza di operazioni e dati necessari per svolgere un particolare compito vengono preparati in anticipo e memorizzati su un adeguato supporto creando una procedura, che viene poi eseguita dal sistema come un blocco unico, cioè senza che sia necessario, o possibile, un intervento umano prima che sia terminata. Il termine è contrapposto alla modalità interattiva, che si ha quando l’utilizzatore accede direttamente ad un terminale o ad una interfaccia dell’elaboratore e segue passo passo le varie fasi dell’operazione. Nei primi sistemi di calcolo la modalità batch era l’unica disponibile: l’utilizzatore preparava in anticipo le schede perforate che contenevano le istruzioni per il sistema operativo, il codice del programma e i dati di ingresso. Il pacco di schede veniva poi consegnato ad un operatore che provvedeva ad inserirlo in una coda di esecuzione. Il risultato era costituito normalmente da una stampa che veniva riconsegnata all’utilizzatore al termine del lavoro.
Per una definizione più appropriata del termine v. |
La procedura, chiaramente, comportava interventi sui documenti tutt’altro che pacifici e neutrali, ancor di più quando le fonti non si presentavano omogenee.
Sostituire le originarie espressioni linguistiche dei testi con codici alfanumerici significava, ovviamente, perdere informazioni potenzialmente preziose e impoverirli dei significati molteplici e complessi di cui erano portatori, con possibili ricadute sulla validità delle elaborazioni compiute.
Una conseguenza immediata per lo storico seriale fu la necessaria consapevolezza di come le fonti utilizzate fossero state, in fin dei conti, costruite per specifiche finalità.
A queste difficoltà si affiancavano le stesse condizioni di utilizzo dei calcolatori, impegnati – per la maggior parte del tempo – al servizio delle facoltà matematiche e fisiche e manovrabili esclusivamente da programmatori esperti, cui lo storico doveva tentare di tradurre in termini informatici le caratteristiche della ricerca in atto.
Gli sviluppi della storia quantitativa suscitarono, naturalmente, accesi dibattiti. Lawrence Stone, capofila degli scettici, ne denunciò a più riprese la metodologia, basata su una retorica dei grafici e delle cifre che finiva – nell’elaborazione dei dati – col dare maggiore peso ad un elemento piuttosto che ad un altro, scegliendo una determinata scala o un determinato indicatore come numero1.
L’attenuarsi, verso la fine degli anni Settanta, delle aspettative nei confronti della storia quantitativa coinvolse inevitabilmente anche l’utilizzazione del calcolatore nella ricerca storica.
Lo stesso Stone ne sottolineò la scarsa flessibilità, derivante dalla necessità di confezionare i dati «in una forma ben precisa, in categorie chiaramente definite, rischiando di distorcere la complessità e l’incertezza della realtà»2 .
Le perplessità dello storico – per quanto radicali – non erano, del resto, immotivate: esprimevano infatti la giusta preoccupazione di riportare la ricerca storica ad una dimensione artigianale del lavoro di ricerca, forse a questo più congeniale.
Come ha rilevato Oscar Itzcovich,
quando, per esempio, [Stone] richiamava l’attenzione sul fatto che il computer impediva quel processo di feedback che è il modo di pensare normale dello storico, che verifica le sue intuizioni sui dati, a loro volta generatori di nuove intenzioni, egli esprimeva l’insoddisfazione per la rigidità di uno strumento che poco aveva a che fare con le consuetudini metodologiche dello storico,
O. Itzcovich, Dal mainframe al personal: il computer nella storiografia quantitativa, in Storia & Computer. Alla ricerca del passato con l’informatica cit., pp. 30-47:34-35. |
Un tentativo di ovviare al problema fu messo in atto, a partire dal 1980, dal progetto di Manfred Thaller denominato CLIO, elaborato presso il Max Planck Institut für Geschichte di Gottingen.
Il programma ideato da Thaller prevedeva l’utilizzo di un database flessibile, per superare le difficoltà implicite nella standardizzazione di informazioni storiche di cui lo storico riconosceva il carattere intrisecamente fuzzy3.
Partendo dal presupposto che le procedure di digitalizzazione delle fonti rappresentavano un’attività onerosa, il software concepito dallo studioso procedeva attraverso la separazione fisica tra i dati, il modello descrittivo e le regole necessarie alla loro elaborazione: in questo modo, sarebbe stata possibile l’immissione di qualunque tipo di attributi desunti dal materiale originale ed eventuali modifiche non avrebbero alterato in modo significativo la struttura concepita4.
CLIO divenne operativo nel 1985 ma non ebbe gran successo, a causa – probabilmente – di un’interfaccia dotata di comandi articolati ed eccessivamente complessi.
Conteneva tuttavia in nuce alcune caratteristiche che negli anni successivi sarebbero state riprese e riorientate nei progressi delle analisi qualitative di fonti disomogenee attraverso la tecnica del record linkage.
Il metodo del linkage prevede il collegamento, all’interno di una base-dati, di informazioni di natura o provenienza diversa. |
Tutte le ricerche citate, dagli anni Sessanta in poi, basavano i propri presupposti teorici e pratici sull’utilizzo dei database e su programmi di gestione dei database (DBMS - Data Base Management System).
La teoria dei database e dei DBMS rappresenta da sempre uno dei filoni più solidi e importanti dell’informatica. Gli RDBMS (Relation Data Base Management System) sono stati creati da Edgar F. Codd, sulla cui base Larry Ellison ha costruito il famoso Oracle, cfr.
Un esempio più recente di ricerche storiche condotte su database è fornito dallo studio compiuto a partire dal 1995 da Robert Rowland su 35.000 processi dell’Inquisizione portoghese a Lisbona, cfr. R. Rowland, Un’esperienza di informatizzazione dei registri dell’Inquisizione portoghese, in L’inquisizione romana in Italia nell’età moderna. Archivi, problemi di metodo e nuove ricerche. Atti del seminario internazionale (Trieste, 18-20 maggio 1988), Roma, Ministero per i beni culturali e ambientali, Ufficio centrale per i beni archivistici 1991 (Pubblicazioni degli Archivi di Stato. Saggi), pp. 401-414. |
 |
In ambito storico, gli archivi di dati normalizzati, gestititi dal computer e strutturati in tabelle univoche e strutture chiuse, sarebbero diventati un’applicazione fondamentale, perché in grado di trasformare il tradizionale archivio dello storico in uno strumento dalle caratteristiche fino allora inimmaginabili5. Ad essere privilegiati furono, per ovvi motivi, i database relazionali che, attraverso record e fields (colonne e campi) messi in relazione tra loro, permettevano di creare connessioni – seppur fittizie e spesso forzate – tra i dati ricavati dalle fonti utilizzate. |
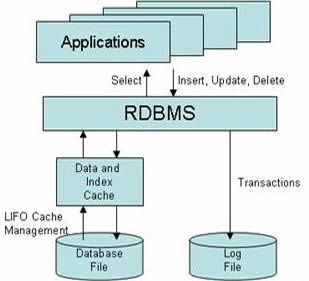
Il grafico riproduce il funzionamento di un RDBMS
Le stesse regole messe a punto da Edgar Codd per definire i requisiti di un Relation Data-Base Managment System, indicano chiaramente i limiti – per la ricerca storica – dell’utilizzo di un sistema basato rigorosamente su tabelle univoche, schematiche e prive di ambiguità.
Le regole sono state fissate nell’articolo di E.F.Codd, Is Your DBMS Really Relational?, pubblicato sul magazine ComputerWorld nel 1985 (la prima parte il 14 ottobre e la seconda il 21 ottobre). Dello stesso autore v.
|
Le fonti storiche, anche quelle di natura seriale, presentano infatti strutture variabili da documento a documento: si pensi, per fare un esempio, alla più classica bolla pontificia.

Escludendo il set di informazioni sempre presenti, riconducibili alle tradizionali partizioni diplomatiche, in ogni diploma è possibile reperire informazioni occasionali e variabili contenutistiche rilevanti: è evidente la difficoltà che una forma documentaria siffatta comporta quando si tratta di definire una scheda per l’introduzione dei dati notevoli, supportata dalla griglia matematica standardizzata su cui si struttura un database.
Il pericolo connesso alla costruzione di un database storico non è quindi quello della cattiva gestione delle procedure che garantiscono, durante il lavoro di immissione, l’omogeneità e l’integrità dell’informazione documentaria, ma consiste nella perdita, durante le operazioni di acquisizione dell’informazione, di tutti quegli elementi giudicati non pertinenti, ma che invece potrebbero fornire chiavi di lettura preziose, permettendo di risalire alle finalità che hanno indotto a produrre l’informazione stessa e ai criteri utilizzati per organizzarla6.
Un approccio selettivo alle fonti, l’efficacia testata all’interno di ipotesi di ricerca tendenti all’ordinario e alla ripetizione e la necessaria immissione di elementi costanti sono i limiti che hanno portato Mario Ricciardi a dichiarare:
Una base dati sottrae tempo storico, segmenti di tempo, successioni di significato fondate sul principio meccanico del rapporto di causa-effetto all’interno dell’ordine del tempo storico. L’attualità della loro leggibilità immediata e della loro composizione-scomposizione fuori dall’ordine prestabilito (o presunto) sconvolge il canone della tradizione,
M. Ricciardi, Letteratura e nuovo mondo, in Scrivere, comunicare, apprendere con le nuove tecnologie, a cura di M. Ricciardi, Torino, Bollati Boringhieri 1995 (Studi e Strumenti), pp. 15-68:40-41. |
Più recentemente, le tecnologie informatiche hanno tentato di fornire una soluzione alle difficoltà incontrate dagli storici nell’acquisizione, gestione e trattamento delle fonti manoscritte attraverso la digitalizzazione delle immagini.
 |
Si tratta di una tecnica meccanica, basata su appositi macchinari – di solito scanner – che, di là della variabilità di hardware e software dedicati allo scopo, è finalizzata ad estrarre dal documento con modalità analogiche un contenuto informativo, inviato a un computer il quale, dopo eventuali filtraggi e formattazioni, lo stabilizza in un nuovo documento digitalizzato. Fra i pacchetti applicativi che da alcuni anni hanno suscitato grandi speranze fra i cultori o i fautori delle applicazioni dell’informatica alle discipline umanistiche, particolare rilievo hanno avuto gli OCR (Optical Character Recognition: riconoscimento ottico dei caratteri), che sono in grado di esplorare un’immagine testuale digitalizzata e riprodurla su un file in cui il medesimo testo è rappresentato in base alla convenzione ASCII o Unicode. |
|
Ma anche questo sistema mostra innumerevoli inconvenienti, soprattutto nel contesto delle testimonianze manoscritte o a stampa ove occorrano – com’è ovvio – imperfezioni o difetti fisici come abrasioni, bruciature, fori, lettere cancellate o illegibili.
In questi casi infatti, il sistema non è in grado di ricostruire la lettera in questione o la scambia per un’altra; anche la versione più recente degli OCR, gli ICR (Intelligent Character Recognition), dotati di dizionari di riscontro per identificare le eventuali lettere non riconosciute, risultano assolutamente inadatti all’acquisizione realmente utile di testi, che vada al di là della semplice evocazione iconografica.
Indubbiamente, la riproduzione su supporto digitale delle splendide pagine miniate di un manoscritto, con la possibilità di conservare l’originale e migliorare il grado di leggibilità del testo originario grazie a tecniche di image enhancement, rappresenta comunque un vantaggio, quantomeno ai fini della divulgazione della cultura e dell’opportunità di visionare testi ubicati a grande distanza.
Un settore che ha particolarmente apprezzato l’impiego delle tecniche di miglioramento dell’immagine è la papirologia, che ha visto nello sviluppo di sistemi di imaging, la possibilità di accostarsi a frammenti papiracei di difficile lettura, come hanno dimostrato gli esperimenti condotti da Duilio Bertani e Luca Consolandi del Centro interdipartimentale di Riflettografia infrarossa e Diagnostica dei Beni Culturali dell’Università degli Studi di Milano a proposito dei famosi papiri contenenti epigrammi di Posidippo e l’opera geografica di Artemidoro.
Nuove prospettive di studio dei reperti a distanza sono emerse nel campo del restauro di pezzi di papiro appartenenti ad uno stesso archivio, ma spesso separati al momento del loro recupero e divisi tra collezioni papirologiche lontane: attraverso i software di gestione delle immagini digitali è stato infatti possibile procedere a restauri virtuali che hanno permesso, ad esempio, la ricomposizione del manufatto e la sua fruizione per lo studio e la pubblicazione.
Un caso illustrativo sono le carte di Ammon, avvocato di Panopoli in Egitto, vissuto del secolo IV d.C., oggi disperse tra Durham, NC, Colonia e Firenze ma felicemente ricongiunte, con tavole virtuali, nel volume dei P. Ammon II, a cura di K. Maresch, I. Andorlini, Papyrologica Coloniensia, Paderborn, Schöningh 2006.
Un quadro delle risorse già disponibili è offerto e aggiornato nel |

|
Tra i progetti di grande respiro nel settore va citato, ad esempio, |
|
 |
Vanno inoltre annoverati
|
|
Tuttavia, un testo riprodotto in un file immagine, anche se formalmente elettronico, non mostra alcun vantaggio ai fini di una ricerca scientifica e anzi soffre di molti limiti, non rendendo fattibili tutte quelle operazioni di interrogazione, utilizzazione di sue parti, di manipolazione del materiale testuale che risultano invece di grande importanza per diversi livelli dello studio storico.

L’acquisizione ottica si rivela, in fin dei conti, una strategia conservativa, che non realizza altro che una più “vivace” edizione meccanica del testo e che rischia, inoltre, di tracciare una strada di comodo suggerendo, anziché la ricerca e l’investimento su nuove progettualità e sul rilancio delle attività editoriali, una digitalizzazione indiscriminata dell’esistente, puntando sull’attrattiva della fonte come immagine piuttosto che sulla sua storia e le sue peculiarità contenutistiche e informative. |
![]()
1 Cfr.
L. Stone, La storia e le scienze sociali nel secolo XX, in
Id., Viaggio nella storia, Roma-Bari, Laterza 1995 (Storia e società), pp. 45-100.
2 Id., p. 45.
3 Letteralmente: nebuloso, cfr. M. Thaller, The need for a theory of Historical Computing, in History and Computing. II, a cura di P. Denley, S. Folgevik, CH. Harvey, Manchester, Manchester University Press 1989, pp. 2-11.
5 Cfr. O. Itzcovich, Dal mainframe al personal: il computer nella storiografia quantitativa, in Storia & Computer. Alla ricerca del passato con l’informatica cit., pp. 30-47:33.
6 Per queste considerazioni cfr. O. Itzcovich, L’uso del calcolatore in storiografia, Milano, Franco Angeli 1993 (Metodologia delle scienze umane, 5), p. 77.